Die Forschungsgruppe Regelungstechnik und Prozessautomatisierung (rtp) arbeitet traditionsgemäß auf folgenden Gebieten:
- Modellbildung und Identifikation dynamischer Systeme
- Digitale Regelung
- Überwachung und Fehlerdiagnose
- Mechatronische Systeme
- Aktorik (elektrisch, pneumatisch, hydraulisch)
- Kraftfahrzeug-Regelung
- Fahrerassistenzsysteme und automatisches Fahren
- Elektronische Steuerung und Regelung von Verbrennungsmotoren und Hybridantrieben
- Modellgestützte Fehlerdiagnose von Benzin- und Dieselmotoren
Frühere Forschungprojekte:
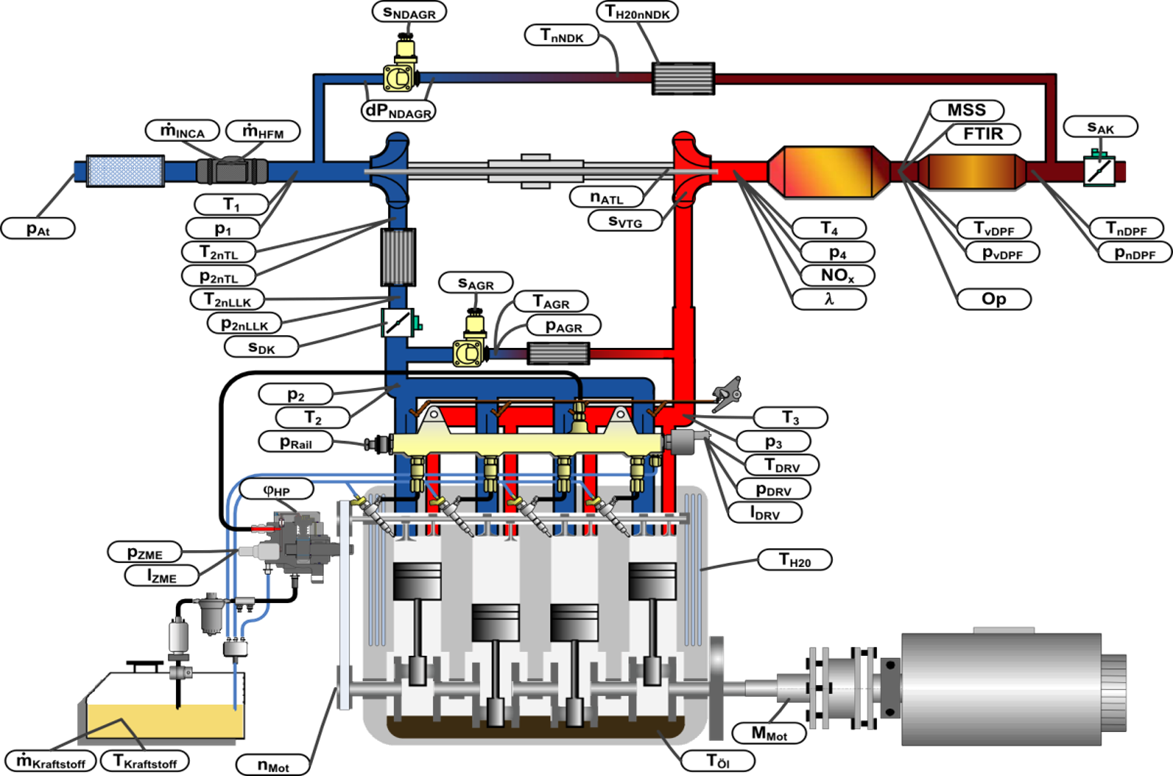
Modellbildung und Regelung von Dieselmotoren
Aufgrund der ständigen Weiterentwicklung, der Kundenwünsche und der Auflagen des Gesetzgebers steigen die Möglichkeiten und Anforderungen an Verbrennungsmotoren weiter an. Neben der Leistungscharakteristik kommen hierbei vor allem den Abgasemissionen und dem Kraftstoffverbrauch sowohl im stationären als auch im instationären Betrieb eine wachsende Bedeutung zu.
Vor diesem Hintergrund werden am Institut für Automatisierungstechnik und Mechatronik neue Verfahren zur Steuerung und Regelung von Verbrennungsmotoren entwickelt. Diese können an verschiedenen Simulationssystemen (z. B. Hardware-in-the-Loop Simulatoren) am institutseigenen dynamischen Motorenprüfstand getestet und optimiert werden. Neben der Steuerung ist auch die modellgestützte Fehlerdiagnose (On-Board-Diagnose) am Verbrennungsmotor in den letzten Jahren zu einem wichtigen Forschungsthema geworden.

Fahrdynamikregelungen, Fahrerassistenzsysteme
Der zunehmende Einsatz mechatronischer Komponenten bei Kraftfahrzeug-Lenkungen, Bremsen und Radaufhängungen zusammen mit der Elektrifizierung der Fahrzeuge erlaubt neue Möglichkeiten fahrdynamischer Regelungen und Diagnosen. Deshalb befassen sich unsere Forschungsvorhaben mit der Modellbildung, Zustandsschätzung und Identifikation des fahrdynamischen Verhaltens mit Anwendungen zur modellgestützten Steuerung und Regelung für Fahrerassistenzsysteme und das automatische Fahren.

Identifikation, Regelung nichtlinearer Prozesse
- Identifikation von dynamischen und statischen Prozessen
- Weiterentwicklung von LOLIMOT
- Anpassung/Entwurf von Identifikationsverfahren an Problemstellungen
- Entwurf von Regelungsstrukturen basierend auf nichtlinearen Modellen
- Internal Model Control
- Anwendungen bei Verbrennungsmotoren und Fahrzeugen

Ausstattung rtp

Motorenprüfstand
- Hochdynamischer Motorenprüfstand 160kW
- Motoren: CR-Dieselmotor und FSI-Benzinmotor
- Rechnergeführte Bedienung des Motorenprüfstands
- RCP-System zur Entwicklung von Motorsteuergerätefunktionen
- Steuergerät-Bypassing mit ES-1000 der Firma ETAS
- AVL-Abgasmesstechnik zur Messung der Abgaskomponente
- Software-Tools zur Vermessung und Kalibrierung des Motorverhaltens
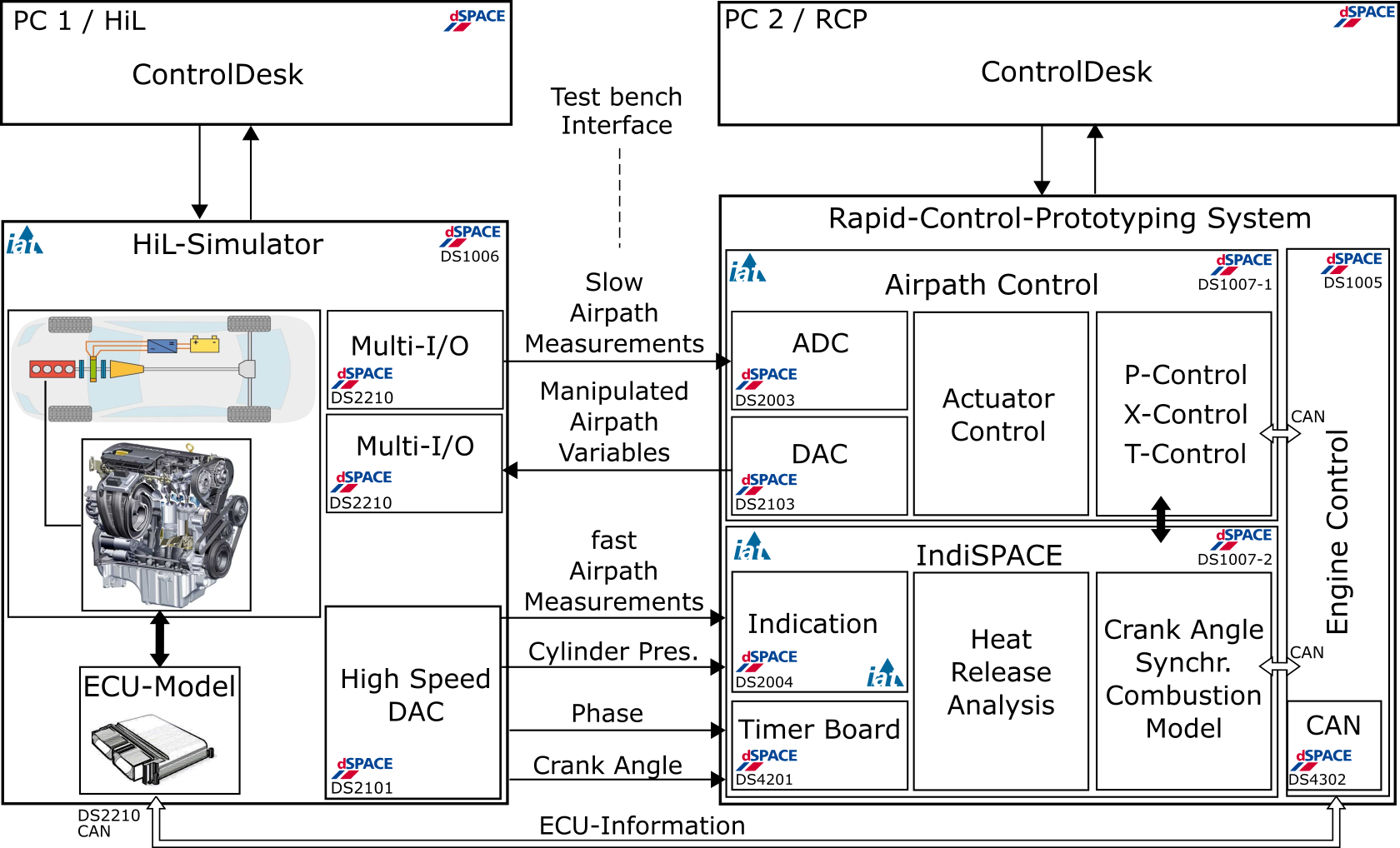
Hardware-in-the-Loop Prüfstand für Rapid-Control-Prototyping System
- Echtzeit-Motorsimulation mit semi-physikalischen Echtzeitmodellen eines CR-Dieselmotors mit VTG und Hochdruck- und Niederdruck-Abgasrückführung
- Mittelwert-Luftpfadmodelle (Luftkanäle, Aktoren etc.)
- Kurbelwinkelaufgelöste Brennraummodelle (Verbrennung, Emissionen)
- Modelle für Sensoren und Schnittstellen zum Motorenprüfstand zur Kopplung mit RCP-System
- Fahrer- und Antriebsstrang-Simulation zur Nachbildung von Fahrmaneuvern und Testzyklen (NEFZ, WLTC,RDE)
- Das RCP-System umfasst ein selbst entwickeltes Indiziersystem und eine Umgebung zur Entwicklung von Verbrennungs- und Emissionsmodellen sowie zur Entwickling von Steuergeräte-Funktionen
- Einfacher Transfer entwickelter Software an den Motorenprüfstand möglich
Veröffentlichungen: siehe Publikationen rtm und rtp
Patente: siehe Patente rtm und rtp
Link zur Präsentation: A brief view back (wird in neuem Tab geöffnet)
